

能使用GPU的OpenAI Whisper語音識別工具(ASR),超快超準確:WhisperDesktop
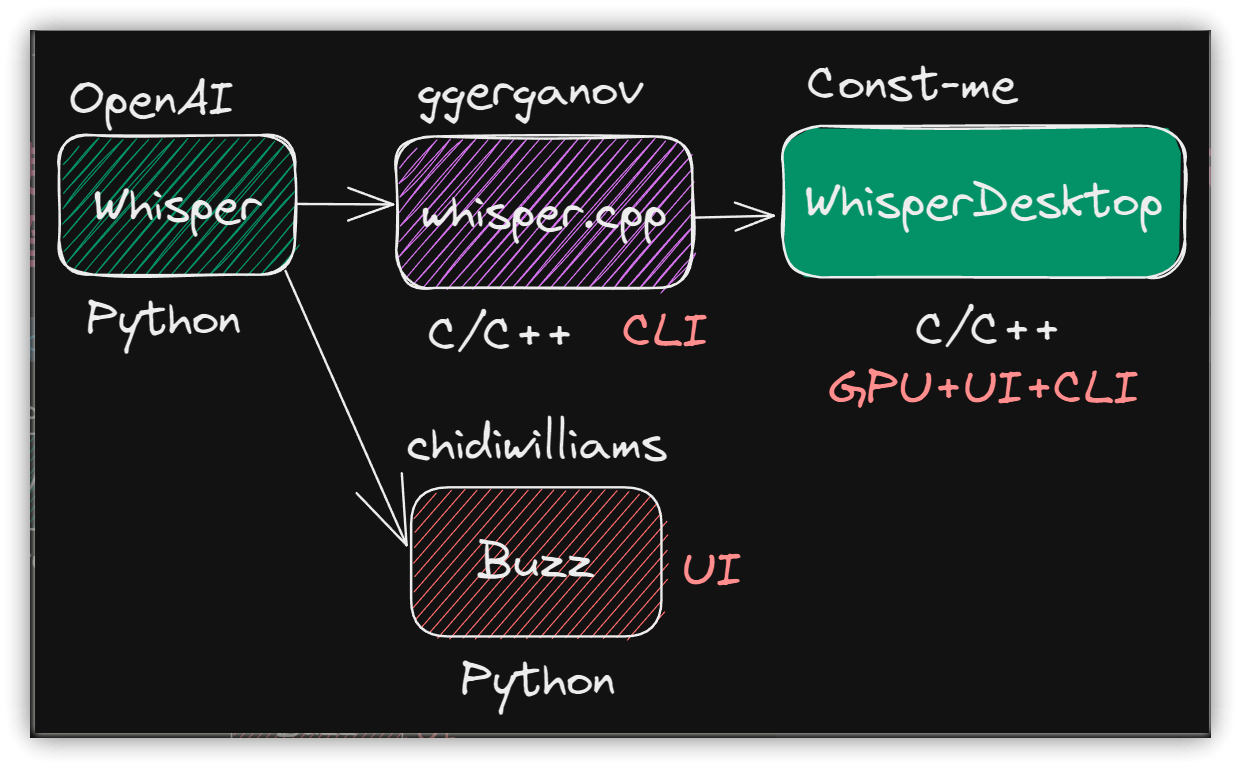
和ChatGPT師出同門(OpenAI公司)的自動語音識別(ASR)工具-Whisper又有了新的增強:除了用C/C++改寫執行緩慢的Python外,也有高手幫它加上了翅膀-也能使用GPU執行了!
還在使用剪映上傳影片以取得字幕的朋友們,Whisper是離線執行,能充份保障影片隱私,現在又有了GPU的並行處理能力,不換Whiper更待何時?
可惜WihsperDesktop目前只有Windows版本,macOS與Linux的朋友們要再等一等。
1. 安裝與執行
- 由GitHub下載Zip檔後解壓縮即可
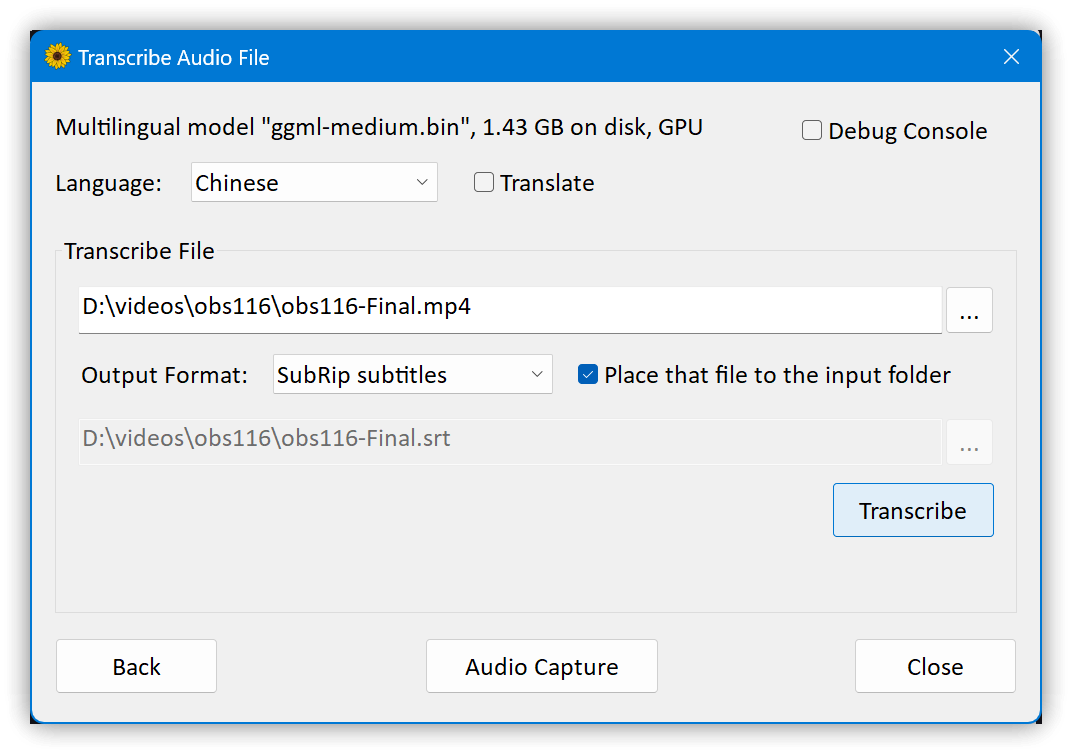
- 下載Model檔案,建議下載ggml-medium.bin檔案(1.5G),可在安裝資料夾建立 models 子目錄,將.bin檔存入
- 執行WhisperDesktop.exe,指定Model檔案,再逐一輸入資料後,按【Transcribe】即可產生需要的輸出格式
2. 命令行
- 須下載cli.zip
- 命令行main.exe只接受音訊檔,因此先用 ffmpeg.exe 將影片檔轉轉換成.wav。
- 音訊檔必須是16MHz
ffmpeg.exe -i "%~1" -ar 16000 -acodec pcm_s16le "%~1.wav"- 指定語音語言為中文(不指定則為auto自動偵測,可能會輸出成英文),輸出格式為.srt,使用medium模型
main.exe -l zh -osrt -m models\ggml-medium.bin "%~1.wav" - 顯示在螢幕上的中文會是問號,但輸出檔案正常
3. 相關鏈接
- ffmpeg下載:https://ffmpeg.org/download.html
- ggml檔案下載: https://huggingface.co/datasets/ggerganov/whisper.cpp/tree/main
- WhisperDesktop Const-me/Whisper: High-performance GPGPU inference of OpenAI's Whisper automatic speech recognition (ASR) model
- Whisper.cpp ggerganov/whisper.cpp: Port of OpenAI's Whisper model in C/C++
- Buzz GitHub
4. 教學影片
##
您可能也會有興趣的類似文章
- 能離線使用的語音識別工具:Buzz,使用OpenAI Whisper神經網路,正確率高 (0則留言, 2022/12/04)
- SE003|Subtitle Edit整合Whisper的使用步驟-快速AI語音轉文字 (0則留言, 2023/10/01)
- SE004|Subtitle Edit 製作雙語字幕的操作步驟 (0則留言, 2023/11/05)
- [AHK#36] 自製AutoSub圖形介面工具:AutoSub-AHK;Windows適用 (7則留言, 2020/05/15)
- 捕捉每次點擊:用Keyviz展示你的按鍵操作,讓教學影片更生動 (0則留言, 2024/04/07)
- [Ubuntu] 使用youtube-dl下載YouTube.com的影片 (0則留言, 2014/02/01)
- 歡迎參觀與訂閱YouTube新頻道:《簡睿軟體頻道》! (0則留言, 2018/02/26)
- Vrew2-【AI技術大揭密】從一句標題自動產出完整影片!腳本、配圖、語音、背景音樂一次搞定! (0則留言, 2023/04/14)
- B站生存手記 (0則留言, 2021/09/23)
- Filmora 12實務04 | YouTuber必看!綜藝字製作技巧,讓你的影片更加精彩獨特! (0則留言, 2023/04/02)
- 使用Subtitle Edit合併兩個.srt字幕檔的方法,讓播放時間自動調整 (0則留言, 2023/08/05)
- YouTube播放清單影片排序的選擇 (0則留言, 2024/04/16)
- AI 降噪! 🙉 Krisp 測試:能有效遮蔽鍵盤打字聲嗎? (0則留言, 2021/04/16)
- 字幕編輯軟體Subtitle Edit的使用技巧 (0則留言, 2020/05/15)
- Filmora 12實務05-製作內嵌字幕的技巧 (0則留言, 2023/10/08)
如果不玩 game 的話,請問有推薦實惠的顯卡嗎?
選購上是先看 VRAM大小還是GPU能力?
用途上是每段1.5-3小時英語的學術會議,想先得到英文逐字稿再依照領域專業順語意
目前只用 Asus prime b660m-a wifi d4 內建顯示晶片算,得用9倍的時間 @@
感謝樓主&各位看倌 ~
抱歉無法推薦,我對硬體並不是太精通。
感謝大大分享,
請教如果不玩game,經費有限的情況下,推薦哪一張顯卡呢?
我用 asus prime B660m 內建圖形晶片算,大概得花8倍的時間產出逐字稿,認真考慮要來找一塊顯卡 @@
不支援32位元作業系統嗎?
似乎只支援64-bit。
只有大約前十分鐘是能夠翻譯 後面都會重複同一句 有方法嗎
換模型也不行嗎?我有轉過1個半小時都正常。真不行的話:
1. 用命令行試試
2. 切換影片成多個10分鐘再把文字檔或SRT檔合併起來
這款速度非常快,美中不足的就是時間戳的樣式無法調整,但我不會命令行,不知道有沒有可能讓輸出的結果只要顯示每一行開始的時分秒就好,不用到秒後的時間、也不用當行結束的時間。
可以用Subtitlte Edit調整時間。可搜尋我的Blog或YouTube影片。